
终于活过来了。
一、背景概述
25年12月,期末周前夕,收到了腾讯云的如下告警。
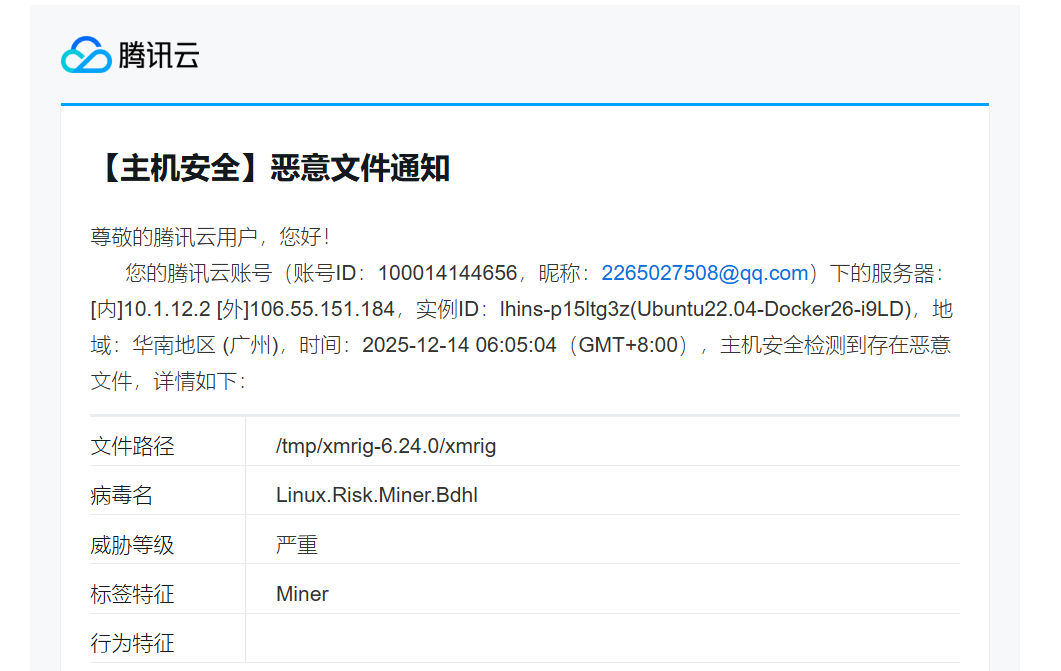
起初我还没当回事,自动查杀了就行了。结果这东西跟蟑螂一样,见到了已经做窝了。

紧接着就是杀毒误伤halo,数据自动回退到8月份。由于有自动备份,我还以为是小事,重新部署恢复就行了。
二、排查思路
这年代居然还有木马,我怀着好奇的心态登上了后台,SSH拷贝走备份文件。但ChatGPT说的吓死人。
这是一次比较典型、而且比较严重的入侵事件,不是 Halo 自己“抽风”。我分 发生了什么 → 为什么会回退 → 现在该怎么救 → 之后怎么防 四步和你说,你先稳住,这种情况是能处理清楚的。
一、发生了什么(从你给的两张图基本可以确定)
1️⃣ 服务器被植入了挖矿木马(xmrig)
腾讯云告警里写得很清楚:
文件路径:
/var/tmp/xmrig-6.24.0/xmrig病毒名:
Linux.Risk.Miner行为特征:Miner(挖矿)
👉 xmrig 是 门罗币挖矿程序,100% 不是你正常业务会用到的东西
👉 说明 服务器被人远程入侵成功,并且获得了执行权限
2️⃣ 入侵者大概率做了这几件事
结合你现在看到的现象,顺序通常是:
扫描到你服务器上的弱点
常见来源(你至少中一个):
Docker 容器暴露端口(MySQL / Redis / Halo API)
MySQL 无密码或弱密码
SSH 用密码登录且密码较弱
旧版 Docker / 旧版 Halo / 旧插件漏洞
成功进入后:
下载并运行
xmrig为了稳定挖矿:
停掉你原本的服务
覆盖 / 删除容器数据
直接用旧数据目录顶掉现有数据
你的 Halo 表现为:
版本回退
数据回到几个月前
你以为的“备份”目录不见了(很可能被删或被旧数据覆盖)
二、为什么 Halo 会“回退到几个月前”
这是重点,你不是幻觉。
从你 ls ~/halo 那张图能看到几个危险信号:
有:
dump.sqlmysql-data-backup-20250827
但:
当前
mysql-data时间和内容明显不对halo-data被整体覆盖过
👉 高度可能发生了:
入侵者用一个旧的
dump.sql或旧的mysql-data
直接docker-compose up,覆盖了你现在的博客数据
这不是 Halo 回滚,是数据被人换过。
三、现在立刻要做的事(非常重要,别跳步)
🔴 第一步:立刻断网 / 停服务(先止血)
docker compose down
然后(强烈建议):
在腾讯云控制台
临时关闭公网
或把安全组只留你自己的 IP
⚠️ 现在不止是博客问题,是整台主机不可信
🔴 第二步:别急着启动,先抢救数据
做一件事:完整拷贝整个 halo 目录
cd ~
tar czvf halo_emergency_backup.tar.gz halo
然后把这个文件 下载到本地保存好。
即使是被覆盖的数据,也可能还有线索(残留数据库、日志)
🔴 第三步:看看有没有“还能救”的数据库
你现在重点检查这几个地方:
1️⃣ dump.sql 内容
less dump.sql
看看里面:
有没有你最近文章的标题
有没有最近评论
如果 dump.sql 是新内容 → 还能恢复
如果 dump.sql 也是旧的 → 数据基本已经被覆盖
2️⃣ 查 Docker 卷是否还有残留
docker volume ls
docker volume inspect <volume_name>
有时候入侵者:
只覆盖了目录
但 Docker volume 还在
🔴 第四步:现实判断(我必须如实告诉你)
如果满足以下 三点:
没有外部备份(COS / 本地 / Git / rsync)
当前
mysql-data是旧的dump.sql也是旧的
那么:
❌ 最近几个月的博客数据,技术上已经不可恢复
这不是你操作失误,是被入侵后的数据破坏。
四、接下来正确的“重建姿势”(很重要)
✅ 1️⃣ 不要在这台系统上继续用
最安全方案(强烈建议):
新建一台云服务器
不要直接复用这台
旧机只用于取证 / 拷数据
✅ 2️⃣ 新服务器最小化暴露面
给你一个安全基线(按你现在的技术水平完全能做到):
SSH
禁止 root 登录
禁止密码登录,只用 key
Docker
MySQL 不对公网暴露
Halo 只走 Caddy / Nginx
防护
开腾讯云主机安全(别关)
开 fail2ban
✅ 3️⃣ 以后备份必须是「三份」
至少:
本机定时
dump.sql同步到 COS / 对象存储
本地电脑一份
博客是内容资产,不是服务资产
五、我可以继续帮你做的(一步一步)
你现在不用自己硬扛,我可以陪你处理完:
✅ 判断 现在还有没有可救的数据
✅ 帮你写 安全版 docker-compose
✅ 帮你设计 自动备份到 COS
✅ 帮你排查 到底是哪个入口被打穿的
你现在只需要回答我一个问题(这个必须知道):
👉 你有没有任何一份不在这台服务器上的备份?
本地
COS
以前下载过的 SQL
Git 里有内容
只要有一份,我们就还有“完整恢复”的可能。
什么系统完整性失信了,容器安全不可信了,不能保证植入后门了,一听到还要重装系统我就不乐意了,那我不能查杀木马,然后恢复备份吗?
GPT好说歹说,查杀了也只是治标不治本,把我劝回来了。重装系统。
同时查找资料,可能是Docker源污染,LTS未更新等。把这些换成官方镜像,部署全新环境,换compose里面的默认密码,想着有备份又不是不能恢复.......结果还真不能恢复。
具体情况就是halo初始化后,上传备份文件,点击恢复。恢复到一半闪退,且前台显示501。
ERROR DefaultNotificationSender-worker-1 aborted with an error
java.lang.IllegalStateException: Timeout on blocking read for 30000000000 NANOSECONDS
run.halo.app.notification.DefaultNotificationSender.sendNotification尝试过用新环境加备份,出事时环境加备份,导出sql.dump,进容器改admin权限,皆不可行。本人水平低下,外加GPT解释,勉强弄懂了MySQL恢复需要时间戳对上,notification / task / job 表的状态要一致
。恢复时NotificationSender 开始 reconcile,导致阻塞式 .block(),所以死循环。
尝试了大概整整两天,太影响复习,还被乔明明cue了,遂放弃。
但特么玄学的事情就来了,回家后,Win上同样的步骤,同样的环境,同样的备份,居然就成功恢复了!我看着恢复的圈圈一直在转,心想怎么还不闪退,不会真的成功了吧,跑去后台一看什么报错都没有,几分钟后还真成功了。
GPT说是在Win上lower_case_table_names=2,而 Linux=0 对大小写敏感的问题。遂拷贝上传,恢复博客。
三、处置与防御建议
发现情况不对立即关闭公网端口,封禁可疑IP,更改所有密码
分析进程列表,查找可疑行为,找到该文件所在目录,检查/tmp等临时目录
养成勤备份的习惯,最好备份与原环境分离
限制服务器不必要的端口开放,加强SSH安全配置(禁用root登录、使用密钥认证)
及时更新和升级系统,修补Confluence、phpunit等已知漏洞


